The Transformer model, introduced in the seminal paper “Attention is All You Need” by Vaswani et al. (2017), has revolutionized natural language processing (NLP) and beyond. Unlike traditional recurrent neural networks (RNNs) or convolutional neural networks (CNNs), Transformers leverage a novel architecture centered around attention mechanisms, allowing for greater scalability and performance. This blog post breaks down the components of the Transformer model, explains how these components work together, and explores what it means when a Transformer model has millions or billions of parameters.
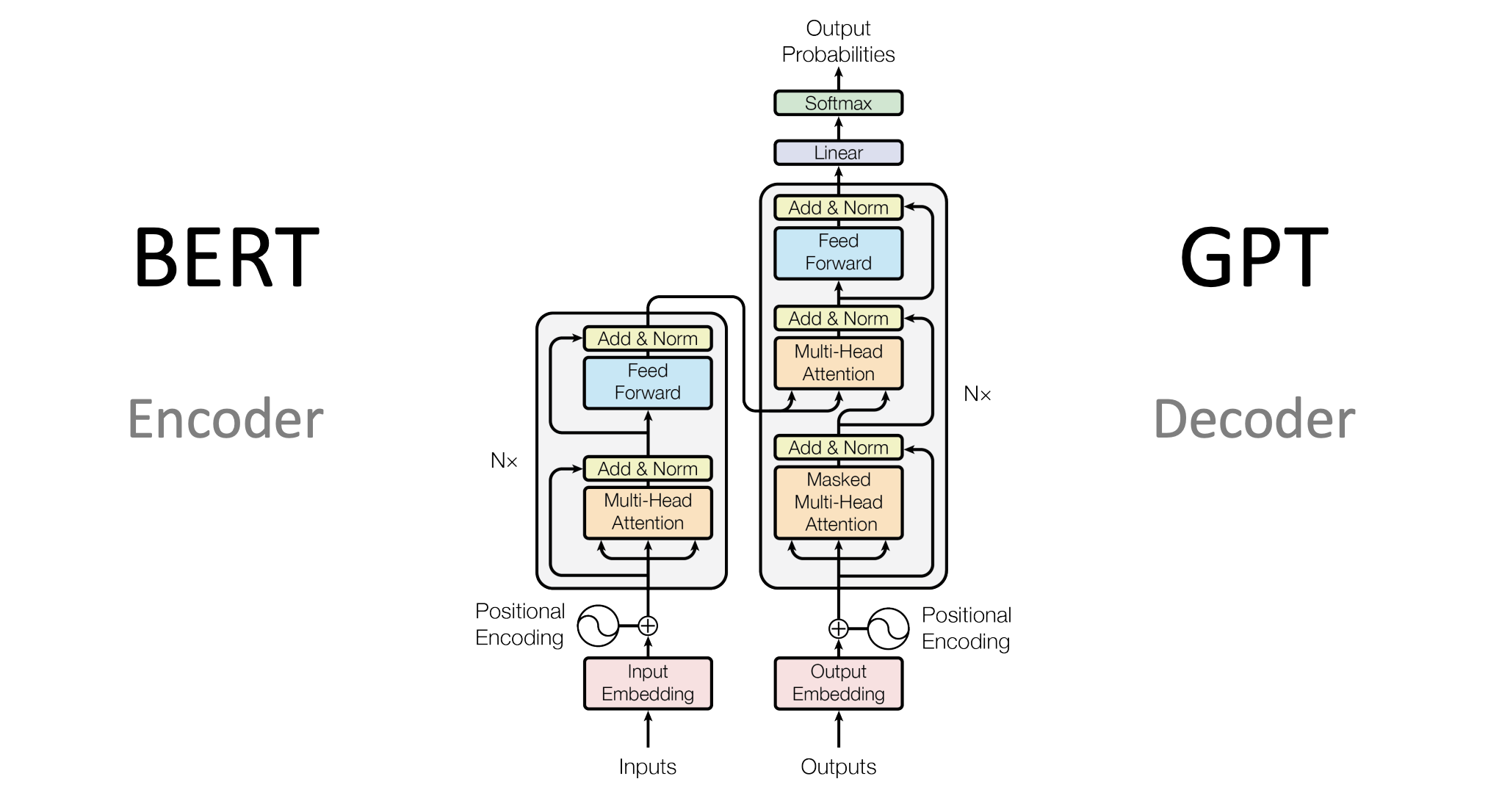 (above image from heidloff.net)
(above image from heidloff.net)
Key Components of a Transformer Model
A Transformer model comprises several key components, including self-attention, positional encoding, multi-head attention, feed-forward networks, and layer normalization. Understanding how these parts interact is crucial to grasping the power of the model.
1. Self-Attention
Self-attention, also known as scaled dot-product attention, is at the heart of the Transformer architecture. Unlike RNNs that process input sequences one step at a time, self-attention allows the model to look at the entire sequence at once. This mechanism computes a weighted representation of the input by measuring how much each word (or token) in a sentence relates to every other word.
For each input token, self-attention calculates three vectors:
- Query (Q): Represents the current token’s importance in relation to other tokens.
- Key (K): Represents the token’s identity and relevance.
- Value (V): Encodes the actual content of the token.
The output of self-attention is a weighted sum of the values, where the weights are determined by the similarity between the queries and keys.
How It Works:
- Compute the dot products of the query with all keys to obtain a score for each token. Scale these scores (to stabilize gradients).
- Apply a softmax function to turn the scores into probabilities.
- Multiply each value by its corresponding probability and sum them up, giving the final attention output.
2. Multi-Head Attention
While self-attention provides a mechanism for capturing token dependencies, multi-head attention extends this by performing several attention operations in parallel. Each “head” learns different representations by focusing on different aspects of the input sequence. The results from all heads are concatenated and linearly transformed into a final output.
This multi-head setup allows the model to jointly attend to information from different positions within the sequence, giving it a richer representation of the input.
3. Positional Encoding
Transformers don’t have any inherent way of understanding the sequential order of the input, as they operate on the entire input at once. To address this, positional encodings are added to the input embeddings. These encodings are vectors that provide information about the position of each token in the sequence.
Typically, sinusoidal functions are used to create these positional encodings, ensuring that the model has a way to distinguish between the order of tokens in the input sequence, which is critical for tasks like language modeling and translation.
4. Feed-Forward Network
Each layer in a Transformer includes a feed-forward network (FFN) applied independently to each position. This network consists of two fully connected layers with a ReLU activation function in between. The feed-forward network helps the model transform the input information into a higher-level representation.
5. Layer Normalization and Residual Connections
To stabilize and improve the training process, Transformers use layer normalization and residual connections. Layer normalization helps regularize the network by normalizing the outputs across the features, ensuring that the activations are centered and scaled. Residual connections allow the model to bypass certain transformations in the network, which helps prevent vanishing gradients and improves convergence during training.
How These Components Work Together
- The input sequence is first embedded and combined with positional encodings.
- This combined sequence is passed into a multi-head self-attention mechanism, which processes the relationships between tokens.
- The attention output is passed through a feed-forward network.
- Each layer output is normalized and connected via residual paths.
- This process is repeated for several layers in both the encoder and decoder stages (in tasks like translation), where the encoder processes the input and the decoder generates the output.
The Meaning of Millions to Billions of Parameters in Transformers
Transformers have risen to prominence due in large part to their ability to scale. When we say that a Transformer model has millions or billions of parameters, we are referring to the total number of trainable weights within the model. These parameters are spread across the various components, such as attention heads, feed-forward networks, and layer normalization layers.
Why So Many Parameters?
Each layer in a Transformer contains many weights, which are learned during training to optimize the model’s ability to understand and generate language. The parameters serve as the knobs that the model tunes to fit the input data:
- Attention Weights: Each attention head has its own set of weights for the query, key, and value vectors. In multi-head attention, each head requires a separate set of these weights.
- Feed-Forward Weights: The fully connected layers in the feed-forward network are densely connected, meaning every input feature is connected to every output feature, creating a large number of weights.
- Embeddings: Word embeddings are learned representations that map tokens into vector space. These embeddings alone can have millions of parameters, especially for large vocabularies.
Why Are So Many Parameters Useful?
- Capacity: A model with more parameters has greater capacity to learn intricate patterns and representations from large datasets. This is especially important in NLP tasks where language can be complex and ambiguous.
- Expressiveness: Large models can capture nuances and subtle relationships between words and phrases, leading to better performance on tasks such as translation, text generation, and summarization.
Conclusion
The Transformer model is a remarkable architecture that leverages self-attention, multi-head attention, feed-forward networks, and positional encoding to process sequential data efficiently. Its ability to scale to millions or even billions of parameters has made it a cornerstone in NLP and deep learning.
When we hear about models like GPT-3 with 175 billion parameters or BERT with 340 million parameters, we’re talking about the immense capacity of these models to learn and generalize from massive datasets. This scalability, however, comes with its own set of challenges in terms of training complexity and computational requirements.
Understanding the architecture of the Transformer model gives us insights into why it has become such a powerful tool for many AI applications today.

